After successfully creating a project on DiVoMiner, you will automatically enter the [Data Management] page. Users who are new to the platform may be a bit puzzled as to what is the difference between these buttons, such as [Coding Library], [Sampling pool], [Test Library] and [Recycle Bin], on the left side of the platform? Which are system-defined databases? What is the role of each?
Within the [Data Management] section, numerous databases can be established, including the [Coding Library], [Test Library] and [Recycle Bin]. Once one or more databases are in place, the [Sampling Pool] can be created by extracting data from the existing database(s).
I. Database Management: The [Coding Library] serves as the foundation for content coding and subsequent analysis.
During the data preparation phase, it is imperative to identify various types of data sources and create corresponding databases. For example, historical literature data differs in format from social media data, and different types of social media data also exhibit distinct formats. To accomplish this, categorize the various data types with different formats and upload them to the corresponding databases within the [Coding Library], then name the databases to complete the establishment process.
It is importent to emphasize that fields across different databases can be shared, requiring only consistent naming of same fields. Subsequent data exploration, online content analysis, statistical analysis, and visualization are all based on the analysis of data within the [Coding Library].
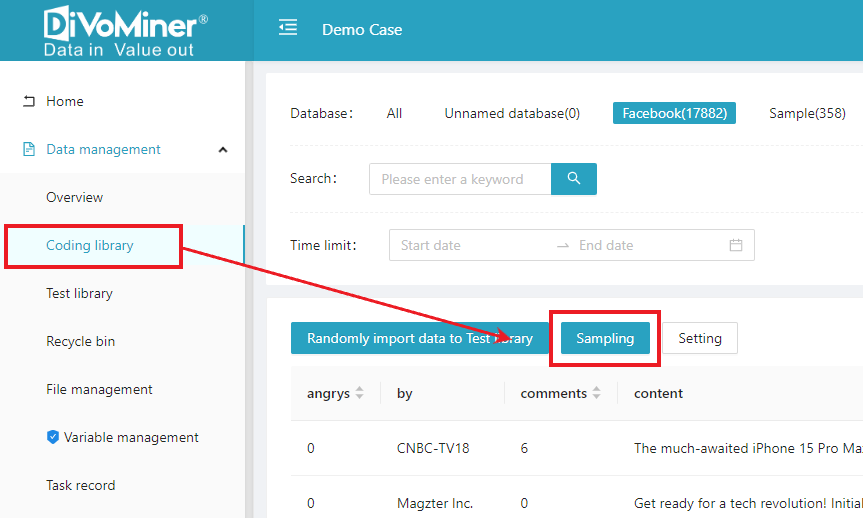
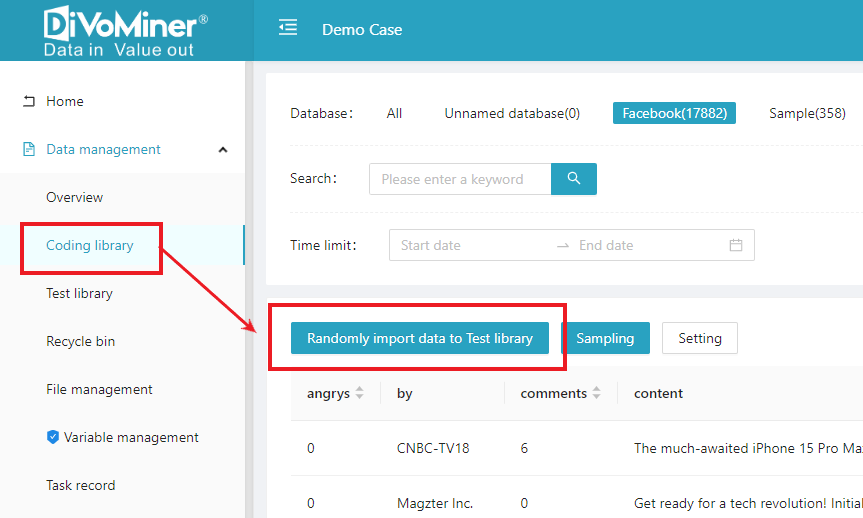
The next step is to establish the [Sampling Pool] or the [Test Library], which also takes place within the [Coding Library] using the functional keys [Sampling] and [Randomly Import Data to Test Library].
II. Sampling Pool – Bringing more possibilities to research methods
As part of the research process design within the DiVoMiner platform, the necessity of establishing a [Sampling Pool] depends on the researchers’ requirements. It is important to note that the platform’s design concept and methodological core revolve around big data technology supporting online content analysis methodology. Thus, given the mammoth volume and complex structure of textual big data, its computational prowess holds an advantage, ensuring the ability to perform calculations on massive textual data within the platform’s scope.
It is necessary to highlight that within the research design framework of the DiVoMiner platform, the [Sampling Pool] and the [Coding Library] exist as independent entities, each operating autonomously. The [Sampling Pool] also encompasses configurations for the [Coding Library], [Test Library], and [Recycle Bin]. Click to explore the sampling methods
III. [Test Library] – Providing data for inter-coder reliability test
The [Test Library] is constructed by extracting partial data from the [Coding Library] and is used for coding test (reliability). Coders are required to perform coding test on the same batch of data, calculating the reliability between coders. Once the reliability reaches an acceptable level of consistency, formal manual coding can commence.
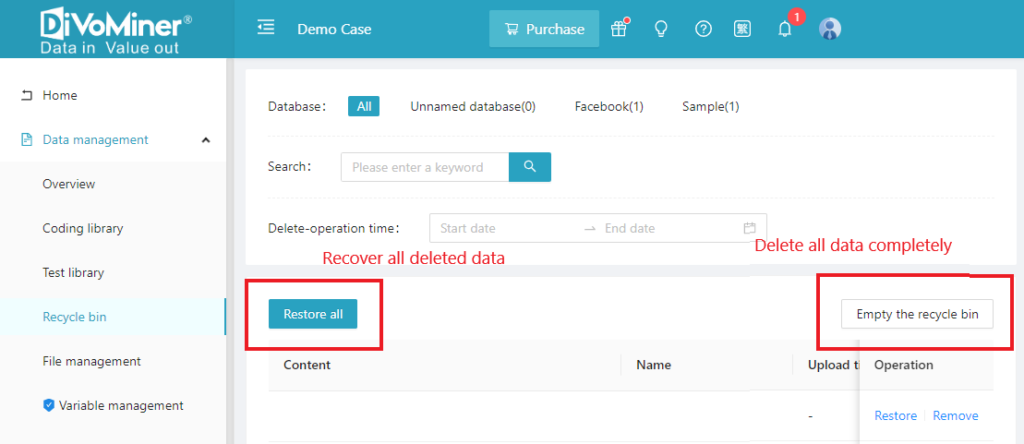
IV. [Recycle Bin] – Storing Cleaned Data After Deletion
All the data deleted after data cleaning will be stored in the [Recycle Bin], you can click [Restore All] in the [Recycle Bin] to recover all deleted data, or click [Empty the Recycle Bin] for complete deletion.