
In the era of big data, the volume of data for analysis is incomparable to that of the past. The emergence of algorithmic coding has undoubtedly given hope to many researchers. This is because algorithmic coding is exceedingly efficient, enabling the completion of data analysis in a very short period of time. Algorithmic coding refers to the approach of using algorithms or computer to mine the internal data rules to obtain data coding results[1]. Researchers can set coding rules and let the computer to execute the coding process on their behalf. As a result, when dealing with massive amounts of data and aiming to process objective textual expressions, the intervention of algorithmic bots becomes an inevitable choice for achieving efficiency.
What is machine coding?
Machine coding, in fact, leverages big data techniques for algorithmic coding. Throughout this process, there is still human intervention, although to a lesser extent than with manual coding. Big data algorithmic coding is usually achieved with manual coding serving as the benchmark. This process is based on the assumption that human understanding of text still surpasses that of machines, and with proper training, humans will make the most accurate and effective classifications of the text[2]. Therefore, the establishment of high-quality coding rules through human effort, together with thorough coding training, can ensure that the level of data quality in traditional manual content analysis is also regarded as the standard practice in content analysis.
At this point, it becomes evident that the accuracy of algorithmic coding still depends significantly on human intervention, especially in the establishment of algorithmic rules, which directly determines the quality of the data. Algorithmic coding, merely executed by algorithmic bots, guides the machine to automatically annotate keywords and fill in response options for the text, thereby enhancing coding efficiency.
Does performing algorithmic coding also need to consider the issue of coding quality?
Scholars such as Song et al. [3] have pointed out that if the quality of manual coding used for validation cannot be ensured, there is a much greater risk of researchers drawing erroneous conclusions about the performance of automated programs. Thus, credibility testing is essential when utilizing algorithmic coding.
However, in many studies, the reliability assessment of algorithmic coding is often overlooked. Song et al. [3] stated that they analyzed 73 studies employing textual automatic analysis, of which 37 reported the use of manual coding for validation. However, only 14 of them fully reported the quality of the manual coding data, with 23 studies not reporting any inter-coder reliability.
It is evident that in the current applications of textual automatic analysis, there is still a prevalent error in ignoring reliability or not treating it seriously. In practice, when using algorithmic coding for text automatic analysis, the first step is to assess reliability, which means inter-coder reliability, as the accuracy of automatic text analysis coding actually depends on the level of definition of coding rules by researchers [4], which also establishes the data quality level of machine learning.
However, ensuring the reliability of manual coding does not complete the evaluation of algorithmic agents. Further assessment should be made of the manually defined rules and their implementation in algorithmic coding.
Therefore, the correct operating procedure for using algorithmic coding should be: first, ensuring the reliability of the human intervention part, i.e., the reliability of the manually established rules; then applying them to algorithmic coding and comparing the consistency between the results of algorithmic and manual coding. Only after achieving consistency between the two can the results of algorithmic coding be used as a basis for interpretation.
The reliability test feature on DiVoMiner not only enables the evaluation of inter-coder reliability, but also evaluates the reliability of algorithmic bots.
Operational procedure for evaluating machine algorithm
Below is a detailed description of the process:
Step 1: Manually set the rules of the algorithm
[Codebook]- [Create a question].
Add [Options] and its corresponding [Keywords] to set the algorithm rules.
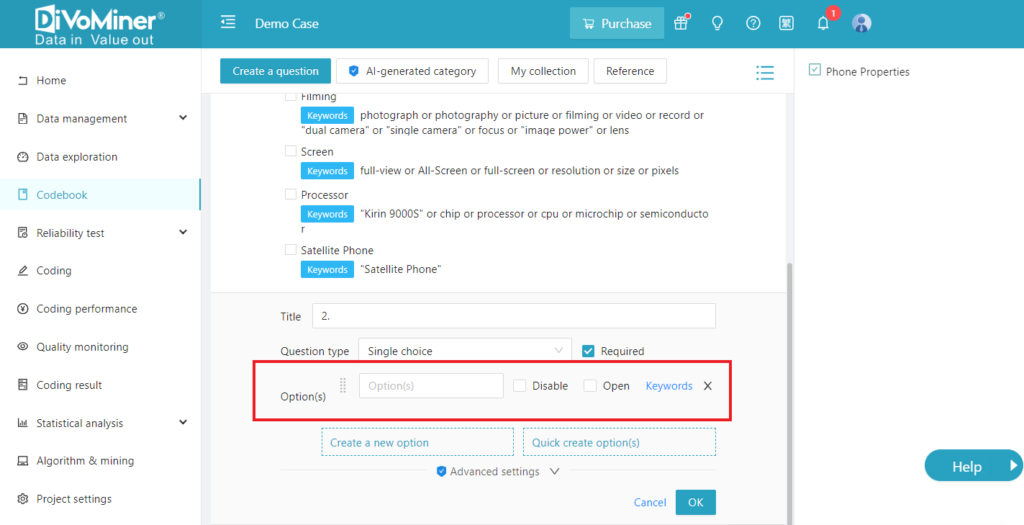
Click here to see the purpose of setting category keywords and rule requirements
Step 2: Create a Test Library
Go to [Data Management] – [Coding Library], click [Randomly Import data to Test Library] to complete the creation of the test library. You can also select a piece of data and click [Test Library] on the right side of the data to import it into the test library individually. Go to [Test Library] to view the imported data.

Step 3: Coding test
To conduct coding test, gather all coders into the [Reliability Test] – [Coding Test] section. All coders are required to read the text, fill in the coding sheet located on the right-hand side of the page, and then click “Save” to finalize the coding process.
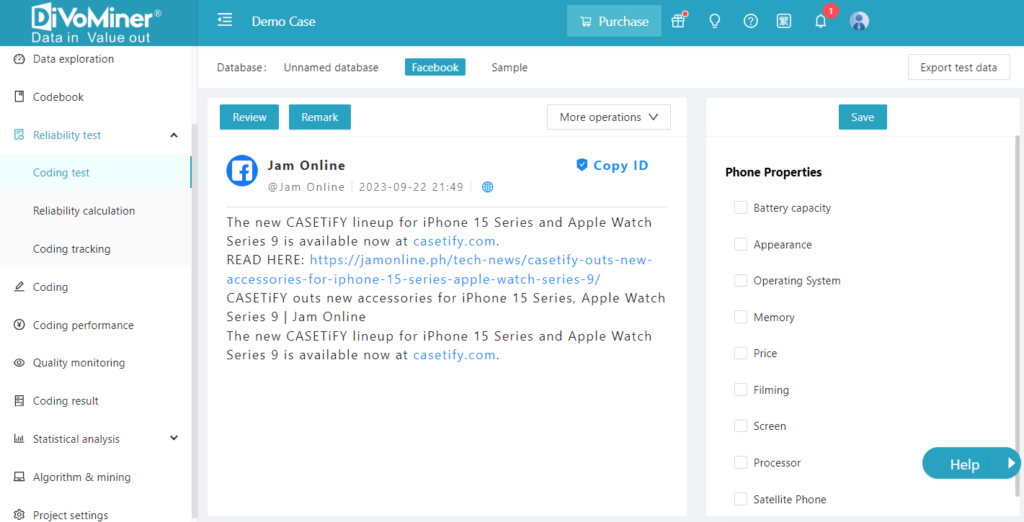
Step 4: Evaluate reliability
After completing the coding test, the reliability coefficient can be viewed immediately. After all coders have completed the coding test, in [Reliability Calculation], select the coder and the reliability index, and click [Calculation] to get the inter-coder reliability results.

Comparing the human-robot consistency. If the reliability meets the standard, it proves that the algorithmic coding results are acceptable, thus the algorithmic bot can be allowed to analyze the textual big data.
TIPS
After completing the coding using the algorithmic bot, the researcher can also view or further correct the results of the machine coding in [Quality Monitoring].
[1] Zmatchamith, R., & Lewis, S. C. (2015). Content analysis and the algorithmic coder: What computational social science means for traditional modes of media analysis. The ANNALS of the American Academy of Political and Social Science, 659(1), 307-318.
[2] Lowe, W., & Benoit, K. (2013). Validating estimates of latent traits from textual data using human judmatchgment as a benchmark. Political analysis, 21(3), 298-313.
[3] Song, H., Tolochko, P., Eberl, J. M., Eisele, O., Greussing, E., Heidenreich, T., Lind, F., Galyga, S., & Boomgaarden, H. G. (2020). In validations we trust? The impact of imperfect human annotations as a gold standard on the quality of validation of automated content analysis. Political Communication, 37(4), 550-572.
[4] Riffe, D., Lacy, S., Fico, F., & Watson, B. (2019). Analyzing media messages: Using quantitative content analysis in research. Routledge.
[5] 程萧潇, 金兼斌, 张荣显, & 赵莹. (2020). 抗疫背景下中医媒介形象之变化. 西安交通大学学报:社会科学版(4), 61-70.
[6] Chang, A., Schulz, P. J., & Wenghin Cheong, A. (2020). Online newspaper framing of non-communicable diseases: comparison of Mainland China, Taiwan, Hong Kong and Macao. International journal of environmental research and public health, 17(15), 5593.