
文本的情感分析(sentiment analysis),分析目的在於瞭解作者在特定文本中的情感態度,這些態度反映了作者在撰寫該文本時的個人情感,或是意圖經由該文本向讀者所傳達的情感。自動化的文本情感分析,是指結合自然語言處理(Natural Language Processing)、文本探勘(Text Mining),以及程式語言等領域的技術方法,來提取文本中的主觀情感資訊。平台所提供的自動化情感分析模型由DiVoMiner®團隊獨家研發,可自動辨別和分析文本中表達的情感或態度傾向(標記為正面、負面或中立),該項技術正在申請專利。
基於團隊對演算模型的不斷升級和豐富的詞彙庫支持,經測試,特定類別語料情感分析Accuracy(準確性或準確率)達到0.7~0.9(業界接受範圍內)。測試結果如下,建議使用者根據實際研究情況確定模型適用性。
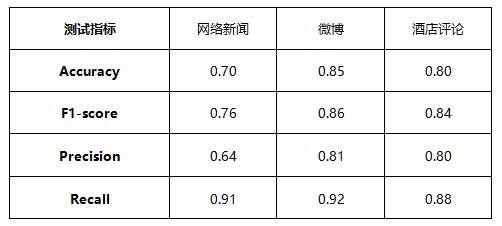
提示:以上測試結果均基於內部資料測試集,而“準度”是建立在特定的測試集基礎上,可通過通用評價指標(如:Accuracy、F1-score、Precision、Recall)給出的量化值進行判斷。受測試集的限制,“準度”範圍會產生波動,目前並無嚴格的業界標準。
指標說明:
- Accuracy(準確率):預測正確的樣本數占總樣本數的比例。【1】
- F1-score(F1值):Precision和Recall的調和平均值。【1】
- Precision(精確率):預測正確的資料占預測資料的比例。【1】
- Recall(召回率):預測正確的資料占實際資料。【2】
參考文獻:
【1】Powers, David M W (2011). “Evaluation: From Precision, Recall and F-easure to ROC, Informedness, Markedness & Correlation” (PDF). Journal of Machine Learning Technologies. 2 (1): 37–63.