
1. Model Introduction
(1). Keyword extraction
a. Automatic word segmentation: extract a specified number of keywords in all texts with TF-IDF algorithm by default;
b. Partly customized keywords: customize keywords, and use the TF-IDF algorithm to extract a specified number of keywords;
c. Fully customized keywords: calculate based on the keywords entered by users.
(2) Word relationship
a. The Jaccard coefficient measures similarity between finite sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets. Namely, the ratio of the frequency of words appearing together to the sum of the frequency of their individual appearances. The larger the coefficient value, the stronger the relationship, and the smaller the coefficient value, the weaker the relationship.
b. Numerical standardization: to facilitate the observation and interpretation of the coefficient results, the numerical standardization method is adopted. The data interval after standardization is (0.1, 1).
(3). Statistical indicators
a. Node Degree: The node degree refers to the number of edges associated with the node, also known as the degree of association.
b. Degree Centrality: The total amount of direct connections between a node and other nodes, normalized by the maximum possible degree. Due to the existence of cycles, this value may be bigger than 1. In a directed graph, the in-center degree (or in-degree) and the out-of-center degree (or out-degree) of the points are divided according to the direction of the connection. It measures the individual value of the node.
c. Closeness Centrality: the reciprocal of the sum of the distances from the node to all other nodes, normalized by the minimum distance. It reflects the closeness of the node to other nodes, the greater the closeness centrality value, the faster to reach other nodes. It measures the value of the node’s network.
d. Betweenness Centrality: the number of shortest paths passing through a node, normalized by the largest possible value. It measures the ability of a node to adjust between other nodes.
e. Co-occurrence: the number of times two nodes appear together.
f. Network Density: is used to describe the density of interconnected edges between nodes in the network. It is commonly used in social networks to measure the density of social relationships and the evolutionary trend.
(4). Word classification (community structure)
In the study of complex networks, a network is said to have community structure if the nodes of the network can be easily grouped into (potentially overlapping) sets of nodes such that each set of nodes is densely connected internally. In the particular case of non-overlapping community finding, this implies that the network divides naturally into groups of nodes with dense connections internally and sparser connections between groups. Based on the heuristic method of modularity optimization proposed by Vincent D. Blondel et al. in 2008. See details:
2. R&D Bases
(1). Wang Gonghui, Liu Weijiang. Are based on keywords of the text information analysis method and its application – An example of credit rating. Sciencepaper Online. 2010.
(2). Han Pu, Wang Dong-bo, Wang Zi-min. Vocabulary similarity calculation and synonym mining research progress. Qing Bao Ke Xue. 2016,34(9):161-165.
3. Algorithm Description
TF-IDF algorithm: to judge whether a word is important in an article, an easy benchmark to think of is the word frequency. Important words often appear multiple times in the article. On the other hand, it is not necessarily important for words that appear frequently. For example, some words appear frequently in various articles, but they are definitely not as important as those words that appear frequently in a certain article. From a statistical point of view, it is to give greater weight to uncommon words, while reducing the weight of common words. IDF (Inverse Document Frequency) is this weight, and TF refers to word frequency.
Jaccard Coefficient: it measures similarity and difference between finite sample sets, and the larger the coefficient value, the stronger the relationship.
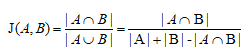
4. Restrictions and Limitations
(1). By default, articles are the basic unit for word co-occurrence calculation. After keywords are set, co-occurrences of any combination of keywords in each article will be calculated. Therefore, the number of keyword combinations and the total number of articles determine the calculation time. Due to the large number of loop iterations, it generally takes a long time and requires high computing resources.
(2). In case of specified keywords, all texts that do not contain the specified keywords will be filtered out. When all texts do not contain the specified keywords, the calculation result is empty.
(3). With regards to the relationship between calculation accuracy, efficiency and resources, if the number of calculation data is greater than 10,000 or the total number of characters is greater than 10,000,000, random sampling is used to extract keywords, and subsequent calculations are still full calculations.
(4). In the context of Chinese-language text, due to the traditional and simplified format, keywords-setting will be automatically expanded to include both traditional and simplified. Therefore, when extracting keywords, the actual number may be more than the specified number of keywords.
(5). The calculation time is limited by many factors (such as network stability, data volume, complexity, operation accuracy, etc.). Refresh the original page to view the calculation results. In most cases, it takes 5-10 minutes. If it is within 30 minutes and you do not see the calculation result, please contact our customer service for follow-up.